有一张shop表如下,有三个字段article,author,price。选出每个author的price最高的记录(要包含所有字段)。
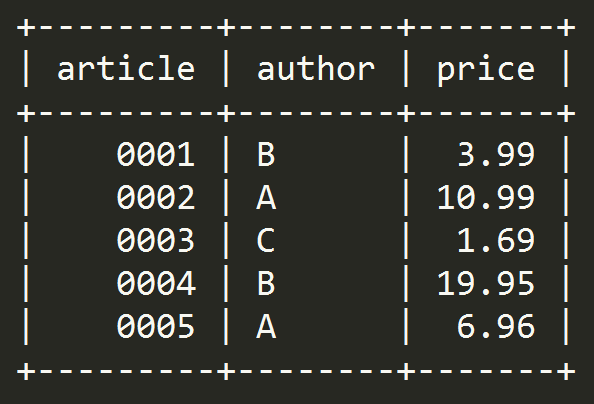
乍一看,一下就想到了这不就是个GROUP BY语句和MAX聚合函数的应用么。
所以,我当时写下如下SQL语句:
|
|
结果一运行,报错如下:
“Column ‘article’ must be in the GROUP BY list”
当然,这个问题并不是在所有版本的MySQL SERVER上都会出现,但毕竟这条SQL语句是有可能会出错的。MySQL的官方文档 MySQL Handling of GROUP BY对这个问题讲解的很清楚详细。
为什么不对呢,这就需要我们注意一点,在返回集字段中,这些字段要么就要包含在GROUP BY语句的后面,作为分组的依据,要么就要被包含在聚合函数中。我们可以将GROUP BY操作想象成如下的一个过程,首先系统根据SELECT语句得到一个结果集,然后根据分组字段,将具有相同分组字段的记录归并成了一条记录。这个时候剩下的那些不存在与GROUP BY语句后面作为分组依据的字段就有可能出现多个值,但是目前一种分组情况只有一条记录,一个数据格是无法放入多个数值的,所以这里就需要通过一定的处理将这些多值的列转化成单值,然后将其放在对应的数据格中,那么完成这个步骤的就是聚合函数,这也就是为什么这些函数叫聚合函数了。
好了,我们知道了上述SQL为什么是错的了,现在我们来说这道题正确的SQL语句:
使用相关子查询
|
|
使用非相关子查询
|
|
由于子查询在有些时候,效率会很低,所以最后提供的方法是用LEFT JOIN语句。
使用LEFT JOIN语句
|
|
上述LEFT JOIN(左连接)语句的原理是:
当 s1.price 是当前author的最大值时,就没有 s2.price比它还要大,所以此时s2的rows的值都会是NULL。
